https://www.ted.com/talks/joseph_redmon_how_computers_learn_to_recognize_objects_instantly#t-436108
인트로 - 이미지 분류
- 10년전(2007)엔 컴퓨터가 개와 고양이 분류 못할거라 생각
- 지금은 99% 이상 정확하게 해냄
- 이미지 분류란 이미지와 라벨을 주어 학습 시키는 것. 수천개의 카테고리에대해 하게됨

소개
- Joseph Redmon
- 워싱턴 대학교, 석사과정, 프로젝트 '다크넷'연구
- '다크넷'은 신경망 체제이며 컴퓨터 시각 견본 교육(Computer Vision Neural network framework)
이미지 분류기
- 하나의 이미지에 대해서 좋은 성능을 보여줌 (개의 종을 예측함) -> 하지만 개와 고양이가 같이 있는 사진에서는?
- 말라뮤트가 있다는 것을 알려주지만 사진 안에 어떤 것들이 있는지를 알려주지 않음


이미지 감지기
- 모든 사물들을 찾아내서 테두리 상자로 표시(로컬라이제이션)
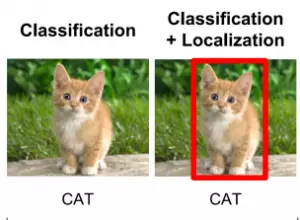

- 자율주행 등과 같은 기술에서 필요한 것은 위와같이 어떠한 것들이 있는지 사물을 감지해내는 기술임
- 종 분류 뿐만 아니라 '사물감지'라는 문제에 대해 연구

이미지 감지기 : 한장에 2초 ~ 초당 5장(Fast R-CNN -> Faster R-CNN)

- 자율 주행 로봇 등의 기술에 활용 가능
- 이미지 하나 처리에 2초밖에 걸리지 않음(이전엔 20초 걸렸음)
- 초당 5장 처리도 가능. 하지만 이정도 수준으로 자율주행에 쓰기는 어려움
YOLO(You Only Look Once)

- 이미지 한장 처리 20초 -> 1/500(1초에 500번 감지) 어떻게 가능?
- 과거: 하나의 이미지를 여러 영역으로 잘라냄 -> 선별작업(점수) -> 가장 높은 점수를 가진 부분을 이미지로 감지. 하지만 한 이미지를 수천 번 분류 작업 하거나 수천 번의 신경망을 거쳐야 하는 단점


- 욜로: 단일 네트워크로 모든 탐지가 가능.
- 모든 테두리 상자와 분류 개연성 동시 처리
- 오직 한번만 보고 탐지함. 그래서 YOLO라고 함

- 이미지 뿐만 아니라 영상 처리도 가능
- 개와 고양이의 인지를 넘어 어울리는 것도 볼 수 있음

개발한 감지기능
- 마이크로소프트의 코코 데이터 세트 사용해서 80개 등급 적용(80개의 카테고리 라는 뜻인듯)
- 숟가락, 포크 등 평범한 물건 ~ 동물, 자동차, 얼룩말 등


- 방청석 줌인

총괄적인 사물감지 시스템(어느곳에나 쓰일 수 있음)
- 자율주행차를 위한 자전거 감지 / 정지표지판 감지
- 조직검사를 통한 암세포 찾기
- 나이로비의 동물 수 조사
-오픈 소스라서 무료임
- 낮은 성능의 컴퓨터로도 가능

YOLO와 컴퓨터비전에 대한 추가 설명
컴퓨터비전의 두가지 질문
- 어떤 물체가 있는가? 이미지 안의 물체가 무엇인지 알려고함(고양이, 개, 사람 등)
- 어디에 있는가? 이미지 안에서 어느 위치에 있는지 찾아냄(중앙, 왼쪽 구석 등)
욜로는 convolutional neural networks(CNN)을 활용함
- 알고리즘을 딱 한번만 돌려야 YOLO의 성능이 나옴. Bounding box(위치)와 Class probabiliity(분류)를 할때 CNN이 사용됨
욜로가 작동하는 방법
- Residual blocks(남는 블록?)
- 바운딩박스 회귀분석
- Intersection Over Union (IOU)
Residual blocks

같은 크기로 나눠진 grid를 볼 수 있음
모든 셀이 오브젝트를 탐지할 것임예) 사각형 안에 물체가 들어간다면 물체를 탐지해냄
Bounding box 회귀
Bounding box란 이미지 안의 물체를 강조 표시하는 박스임모든 Bounding box는 다음과 같은 속성을 가짐$폭(b_w), 높이(b_h), 박스 중심점(b_x,b_y), Class(c, 사람, 자동차, 고양이 등), p_c(해당 클래스에 대한 확률)$
hi

Intersection over union(IOU)
- 어떻게 box를 오버랩 할것인지
- YOLO는 물체를 완전히 감싸는 박스를 제공하기 위해 IOU사용
- 각 박스는 Bounding box 예측과 자신감 점수를 담당함
- IOU가 1이라는 뜻은 박스가 정확히 물체를 감싸고 있단느 뜻

세가지 기술 조합

1. 이미지가 grid로 나뉘어짐
- Boudning box와 자신감 점수를 제공
- 어떤 class에 속하는지 예측함
위의 그림에선 강아지, 자전거, 자동차 예측 가능하며 single CNN으로 예측함
IOU는 예측한 bounding box가 실제 물체의 사이즈에 맞는지 검증함
- 불필요한 bounding box를 없앰 -> 물체에 꼭 맞는 박스를 생성해냄
https://cv-tricks.com/object-detection/faster-r-cnn-yolo-ssd/
Zero to Hero: Guide to Object Detection using Deep Learning: Faster R-CNN,YOLO,SSD - CV-Tricks.com
In this post, I shall explain object detection and various algorithms like Faster R-CNN, YOLO, SSD. We shall start from beginners' level and go till the state-of-the-art in object detection, understanding the intuition, approach and salient features of eac
cv-tricks.com
https://www.section.io/engineering-education/introduction-to-yolo-algorithm-for-object-detection/
Introduction to YOLO Algorithm for Object Detection
This article will cover the basics of the YOLO algorithm for object detection. It will take readers through aspects such as the importance, working, and application of this algorithm.
www.section.io
'기타 > 공부노트' 카테고리의 다른 글
| 가트너 하이프사이클 보는 법 (0) | 2021.09.04 |
|---|---|
| [구글 AI 블로그] 페가수스: 최첨단 추상화 텍스트 요약 (0) | 2021.08.07 |
| [스터디 팁] 강의노트 적는법 (Feat. 코넬노트) (0) | 2021.06.04 |
| [Mckinsey] 과대 광고 이상의 블록체인: 전략적 비즈니스 가치는 무엇입니까? (0) | 2021.05.23 |
| [Ted]Why you think you're right — even if you're wrong (0) | 2021.05.22 |