강화학습이란?
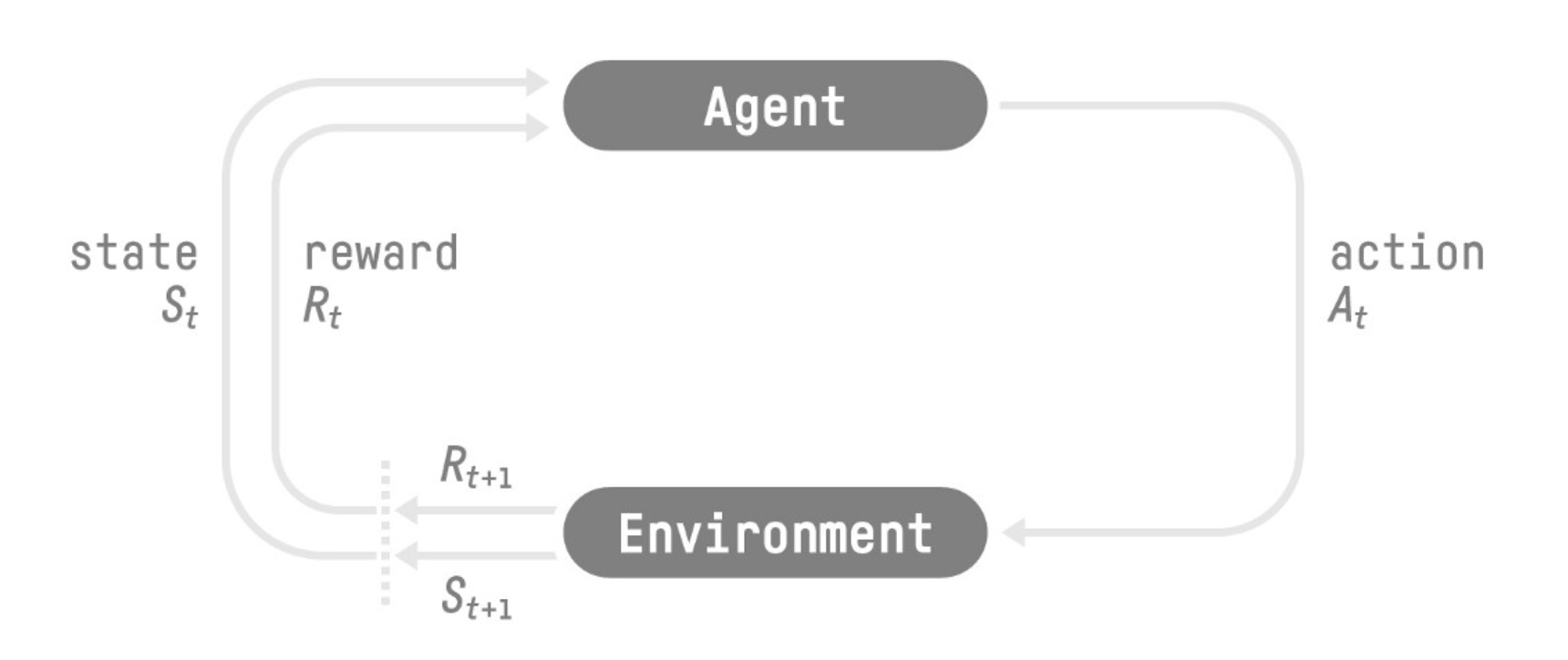
Agent가 주위 환경과 상호작용을 통한 보상을 이용해 학습하는 방식. 보상을 통해 따로 감독없이 학습 가능
예) 게임환경에서 상호작용을 통해 학습하는 게임 플레이어
공식 정의
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
게임 예시
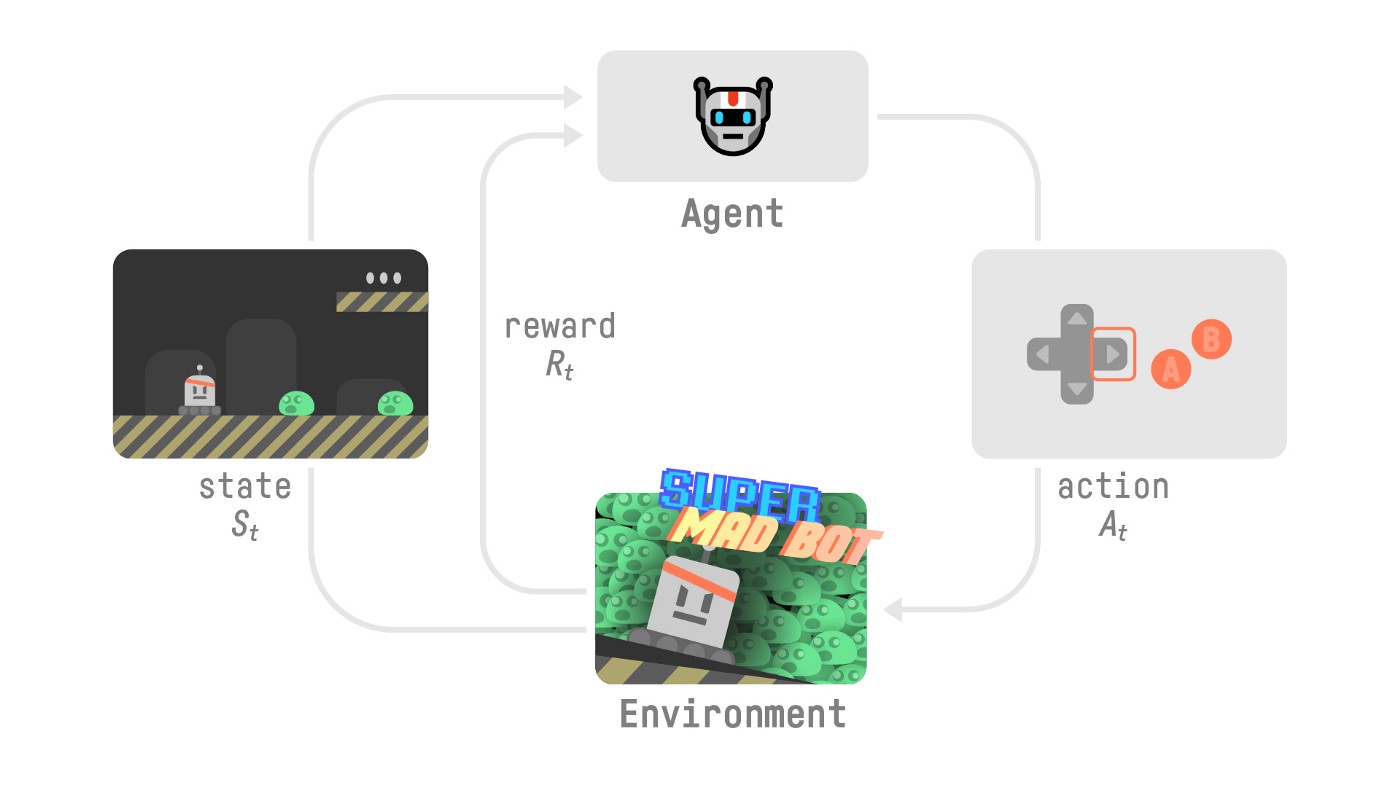
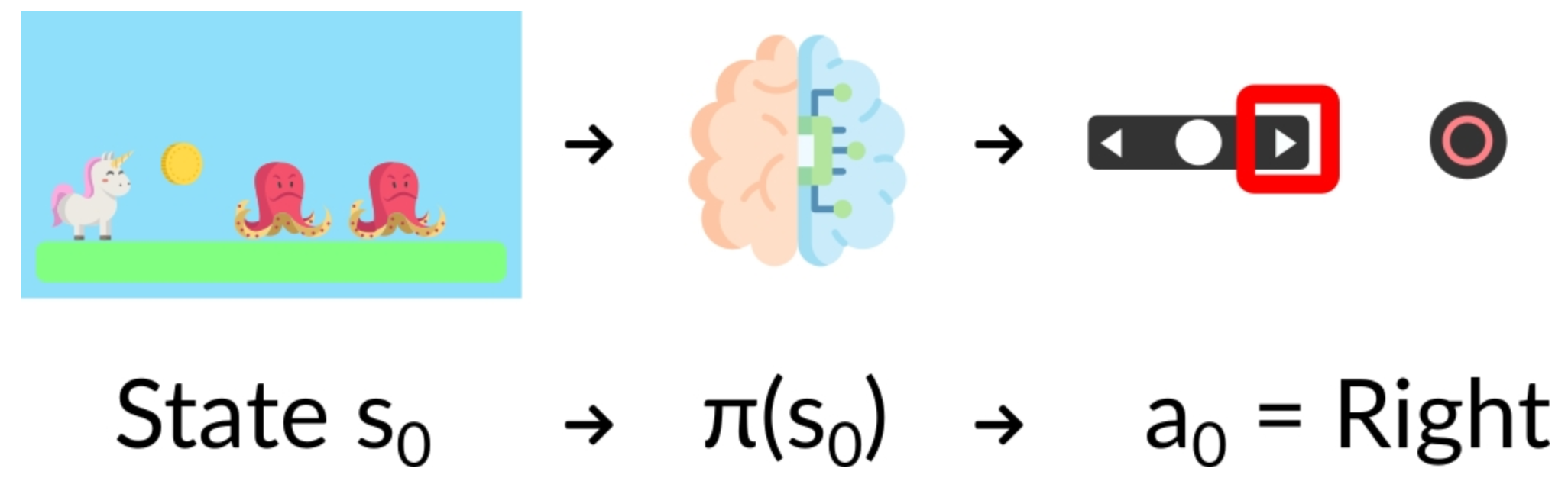
- 게임환경에서 첫 프레임을 받게 됨()
- 에서 행동()을 택함. 예를들면 오른쪽으로 이동
- 오른쪽으로 이동함으로 다음 프레임()으로 변경됨
- 이때, 캐릭터가 사망하지 않는다면 보상()을 받게됨
위와같은 State, action, Reward, Next state,…을 반복하게 됨
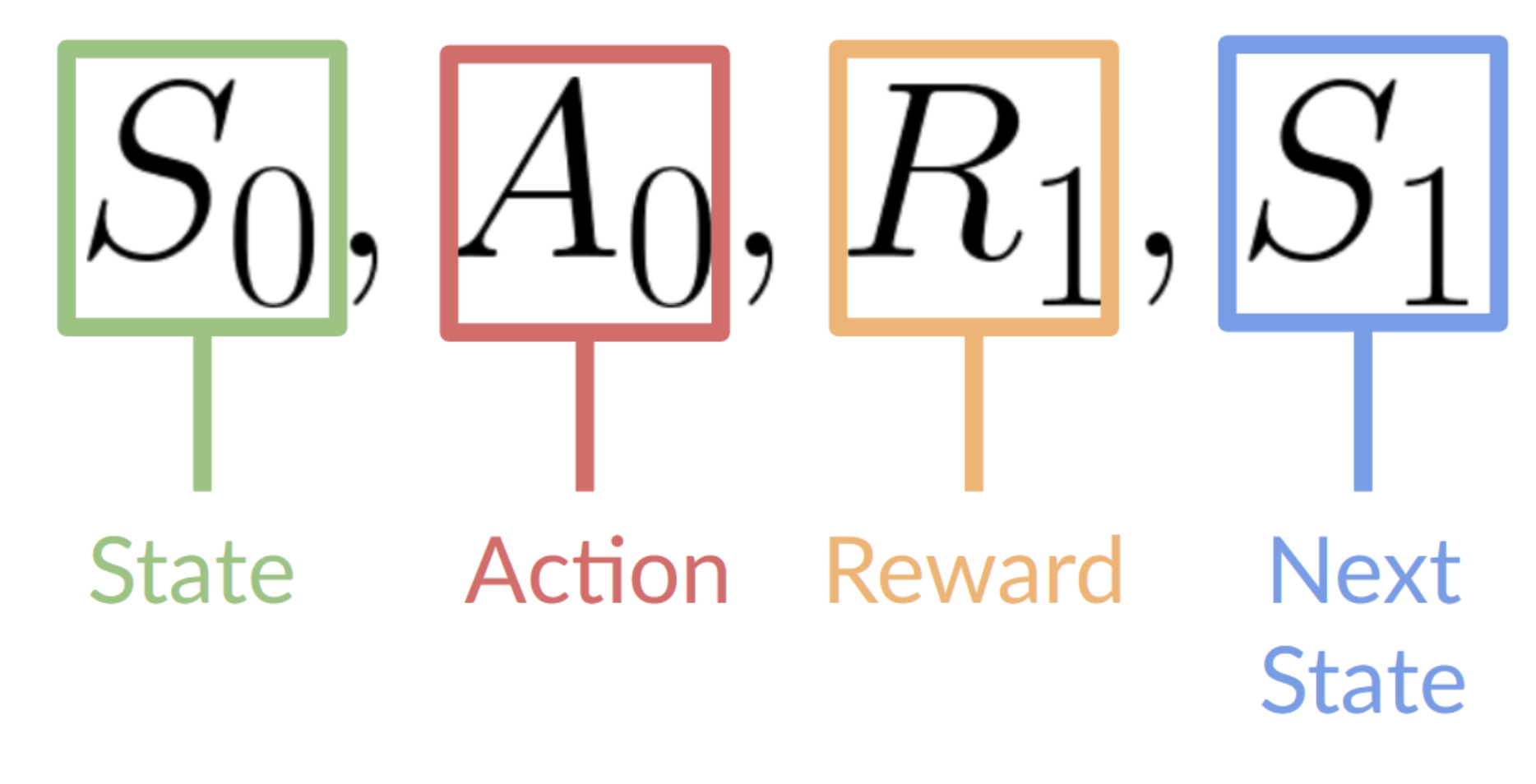
에이전트의 목표는 기대 수익(expected return)을 최대화 하는 것임. 기대수익은 경제학에서 이야기하는 현재가치로 설명 가능
Markov property
이 내용은 다른 강의를 듣게 되면 상당히 길게 설명하는 부분임. 상당히 길게 이야기 하지만 핵심은 에이전트가 오직 현재 상태를 기준으로 내린다는 것. 달리말하면 현재 상태가 과거의 상태를 요약해서 가지고 있다 할 수 있음(대학원 수업때 교수님이 한 말)
Observation / State
에이전트가 환경으로 부터 얻는 정보를 뜻함. State를 , Observation을 라고한다면 ==== 으로 표현할 수 있음. 주식거래 봇 이라면 특정 주식의 가격이, 게임이라면 한 프레임이 위 값에 해당할 수 있음
observation과 state의 차이
둘은 거의 유사하지만 위에서 언급했듯 observation은 state에 포함됨. 즉 state는 state world를 모두 표현한 것이고, observation은 state 중 일부를 표현
state

State는 agent가 판단을 하기위해 숨겨진 정보가 없는 상태. 달리 말해 fully observed state.
observation
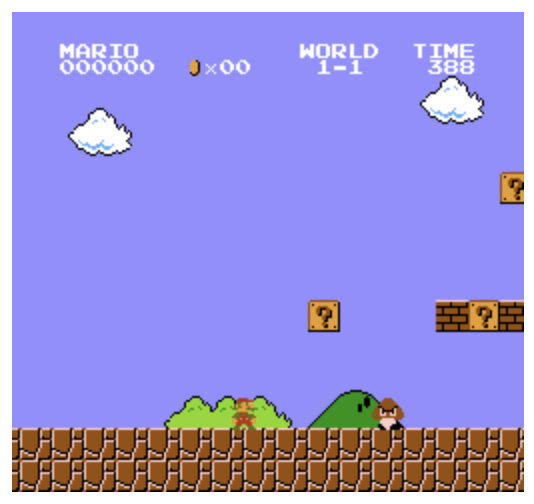
Observation의 경우 state의 일부만 볼 수있음. 즉 위의 마리오 게임의 경우 위 프레임 다음에도 여러 프레임이 존재함. 따라서 위의 프레임은 모든 state를 표현하지 못하기에. Observation에 속함
Action space
환경 안에서 가능한 모든 행동을 뜻함. Discrete 경우와 continuous 경우가 있음
Discrete = finite
Discrete의 경우 제한된 숫자의 행동만 가능
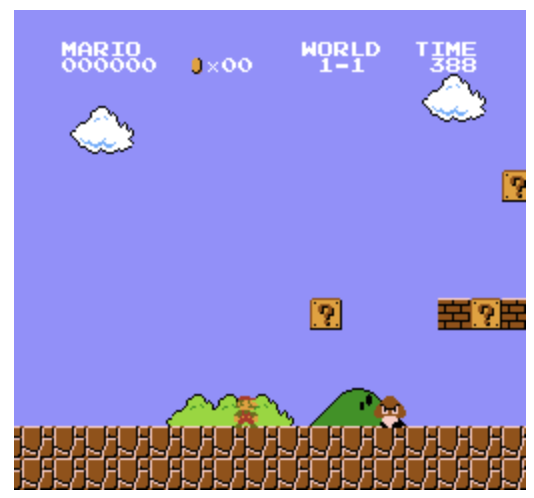
위 마리오 게임의 경우, 위,아래,좌,우 의 4가지 행동 중 선택가능.
Continuons = infinite
Continuous 의 경우 가능한 행동이 무한대임.

가령 자동차 운전의 경우 핸들움직이기(0,0.1,0.2,…), 경적울리기, 기어바꾸기, 브레이크 밟기 등 거의 무한한 행동이 가능함
테스크의 종류
Episodic task
시작과 끝이 정해진 경우. 게임의 경우, 게임을 완수하거나 아니면 캐릭터가 중간에 사망하는 경우로 나눌 수 있음.

마리오 게임의 경우 Episodic task의 한 종류임
Continuing Task
끝나는 시점이 없는 경우. 이때 에이전트의 일은 최선의 행동을 하면서 동시에 환경과 상호작용을 하는 것. 따라서 에이전트는 우리가 정지 신호를 보낼때 까지 계속 학습하게 됨. 예를들어 주식거래 에이전트를 만들게 되면 해당 경우에 시작과 끝점이라는 것은 존재하지 않음
주식거래 예시 이미지
Exploitation / Exploration
한국말로는 착취(여기서는 기존방법 고수라고 표현하겠다)와 탐험으로 해석되지만 요지는 기존 방식을 그대로 유지할지 또는 새로운 방법을 시도하는지의 차이로 볼 수 있다. 가령 다음과 같은 예를 통해 살펴 볼 수 있다
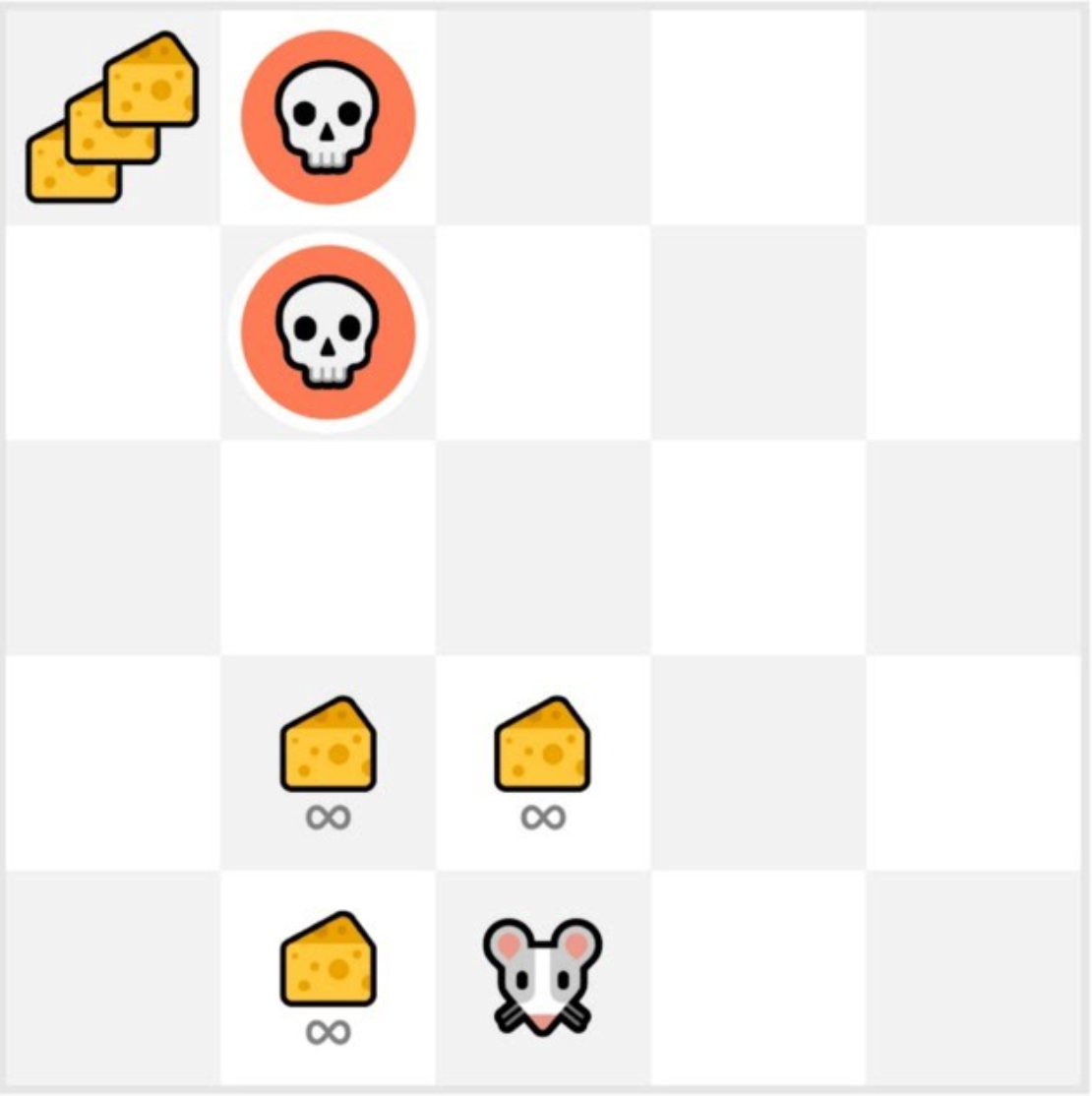
위 그림에서 치즈 1개는 +1의 보상을 뜻하고, 치즈 3개는 +1000의 보상을 뜻한다. 그리고 직관적이게 해골은 사망을 뜻한다.
만약 쥐가 충분한 탐험을 하지 않고 기존방법을 고수하게 된다면 주위의 3개 치즈만 보상으로 받으며 기대 보상을 최대화하기 힘들 것이다.
반면 충분한 탐험을 하게 되면 왼쪽위의 +1000의 보상을 통해 더 큰 기대 보상을 만들어 낼 수 있다. 해당 결과를 그림으로 표현하면 아래와 같다.
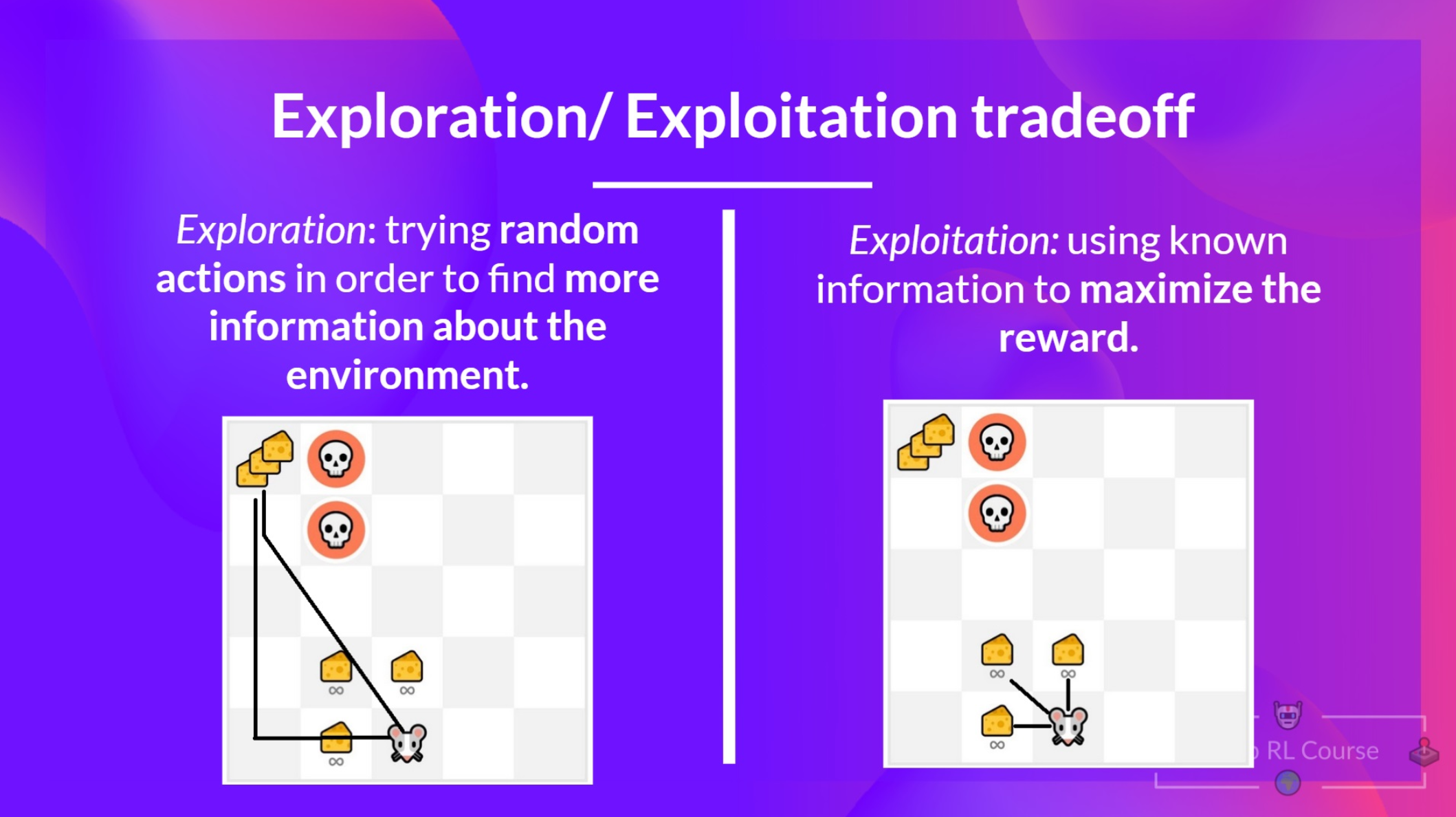
위 그림과 같이 충분한 탐험이 전재되지 않은 상태에서 기존방법을 고수하게 되면(오른쪽) 상대적으로 작은 기대 보상을 받을 수 있고, 충분한 탐험을 하게되면 높은 기대 보상을 받을 수 있다.
강화학습 문제를 해결하는 두가지 방법
위에 나온 내용들은 강화학습의 전반적인 문제를 다뤘다. 그렇다면 이를 어떻게 해결할 수 있는지 알아봐야 한다.
The Policy π: the agent’s brain
- Policy 는 agent의 뇌처럼 작동함
- 주어진 state에서 행동을 알려주는 기능을 함
- 주어진 시점에 해야하는 행동을 나타냄
- Policy가 우리가 학습시키고자 하는 것
- 최적의 Policy를 찾는게 우리의 목표임 .
- 최적의 Policy란 기대보상(expected return)을 최대화 하는 것임
- 를 찾는 방법은 두가지가 있음
- Policy-based method : 주어진 state에서 어떤 행동을 취해야 할지 직접적으로 배움(?)
- Value-Based Method : 어떤 상태(state)에 있는 것이 더 가치있는지 알려줌으로서 더 가치있는 상태로 가는 행동을 학습시킴
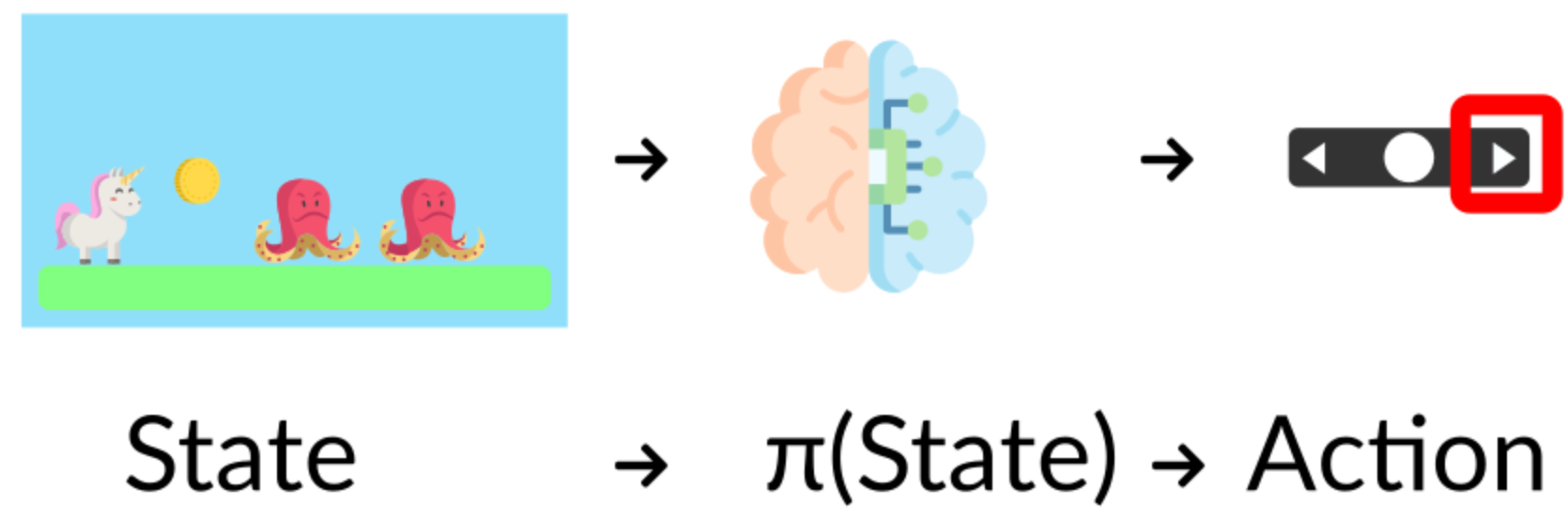
Policy-Based Methods
- 직접적으로 배운다. 각 state의 value를 학습시켜 간접적인 Trajectory를 만드는 방법이 아님. 해당 state에서 action을 Deterministic 또는 stochastic(행동의 확률 분포) 하게 표현함
- 각 state에서 최적 액션의 mapping을 정의함. 또는 해당 State에서 취해야 할 행동의 확률 분포를 생성함

- Deterministic: a policy at a given state will always return the same action.
- Stochastic: outputs a probability distribution over actions.
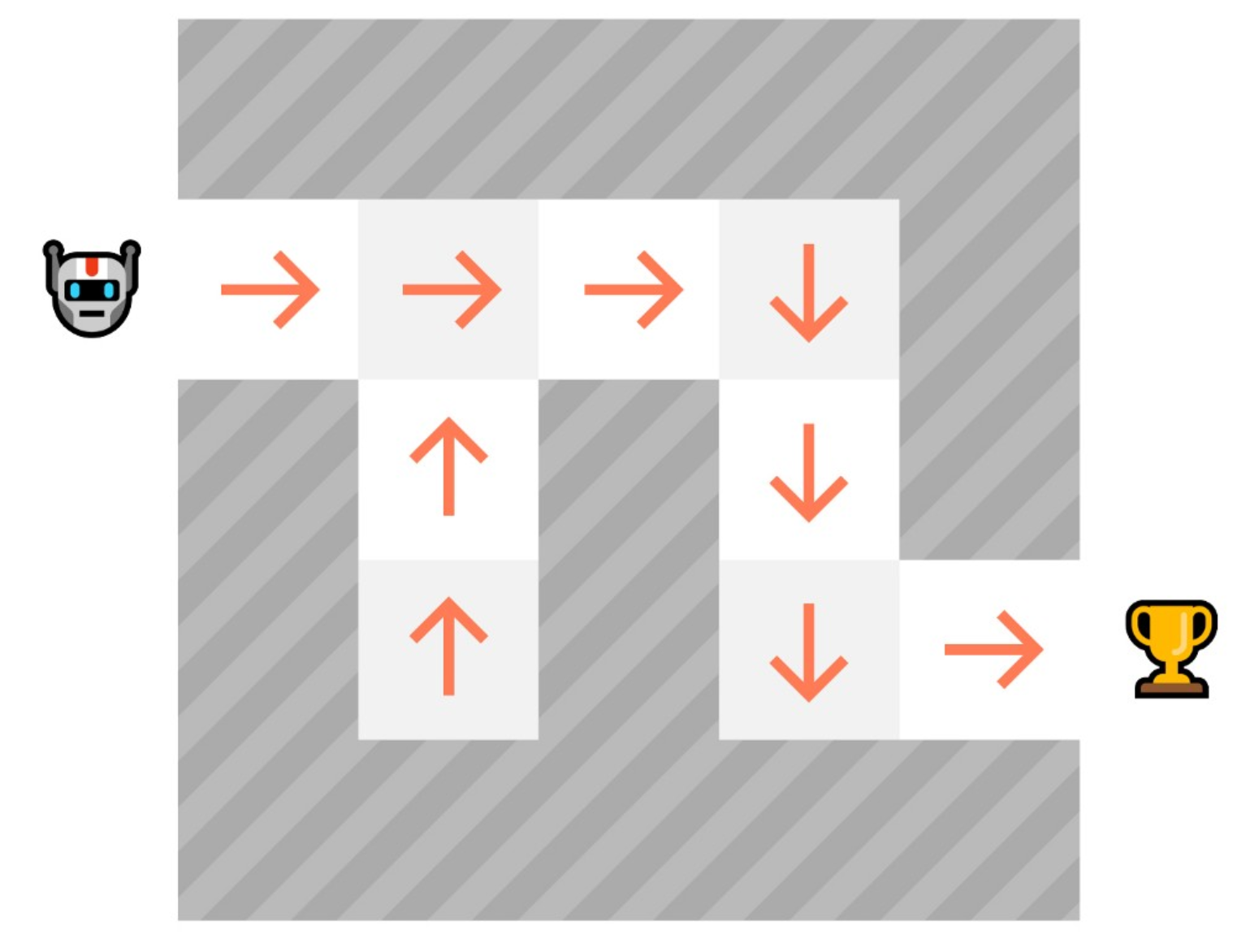

Value-based method
- 어떤 상태가 될때 기대 보상 function을 학습시킴
- 해당 state의 값은 expected discounted return(경제에서 말하는 annuity)
- 어느 한 state에서 시작해, 해당 Policy를 따라갈 때 얻을 수 있는 보상으로 정의함
- Policy를 따른다는 것은, "가장 높은 값을 가지는 state방향으로 가는 것" 을 뜻함
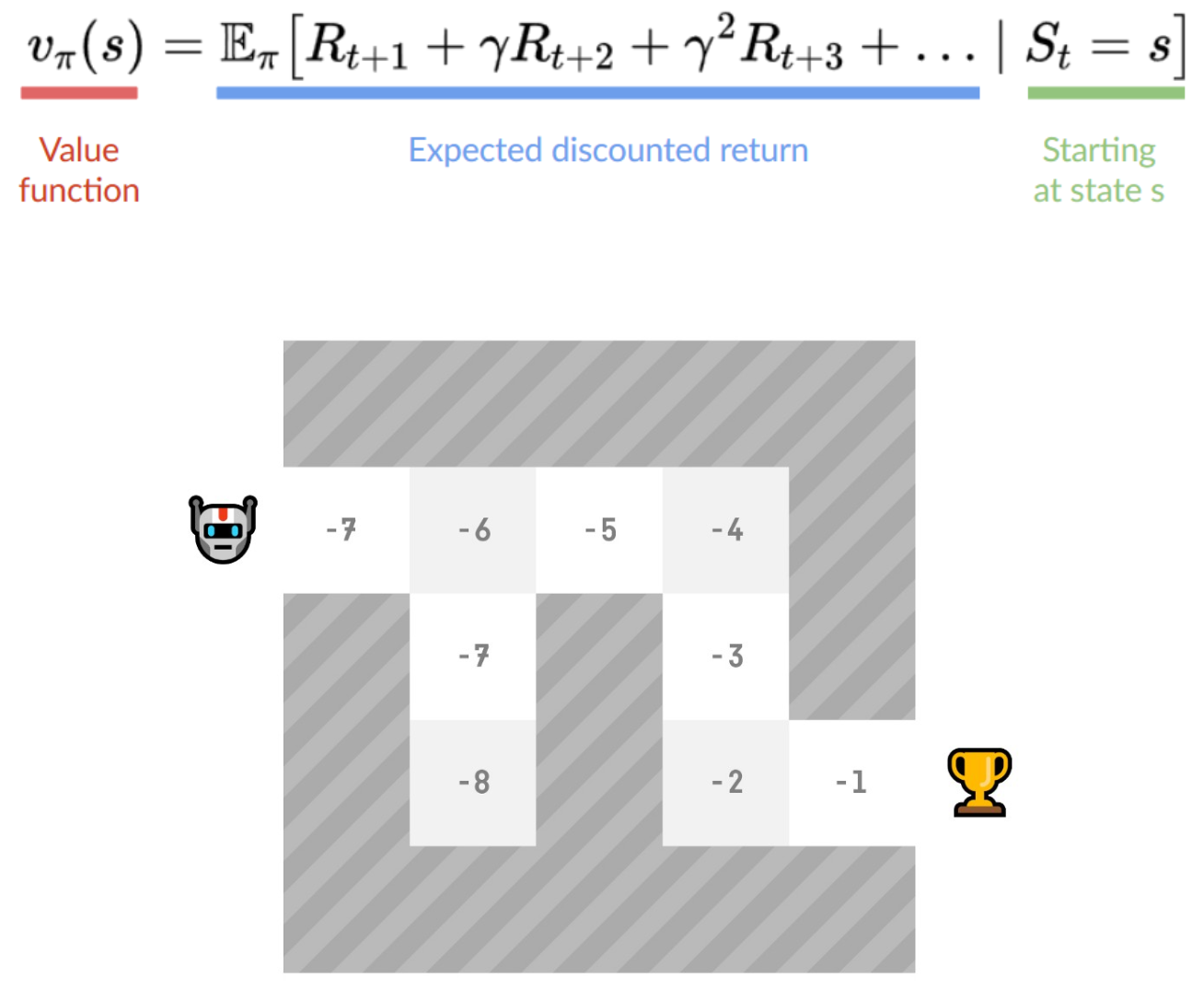
My Summary
스터디 질문
- Policy-based 와 value-based 차이가 잘 이해가 가지 않는다.
- 보물찾기 게임을 예로들면 value-based는 각 위치의 기대보상을 써놓는 것이고
- Policy-based는 그 위치에서 무슨 행동을 해야할지를 써놓은 것이다.
- 보물찾기로 예를 통해 value-based의 단점과 Policy-based의 장점을 볼 수 있다. 예시 2 Aliased Gridworld
- Policy 방식이 다르다고 하지만 결국 reward를 정의해야 할 것. 이때 state value는 필요 없는건가?
- value-based가 간접적으로 discounted expected Return이 가장 높은 방식을 찾는다면, state가 discrete하지 않는 경우 메모리에 문제가 생기지 않을까?
- infinite state space
'아카이브 > Reinforcement Learning' 카테고리의 다른 글
| Ch-2 Multi-armed bandit Q(a) 파이썬 코드 (0) | 2023.12.10 |
|---|
