데이터 저장 위치 설정
여러 데이터를 저장하는 위치인거 같습니다. 그 중 가장 중요한 기능은 *.cypher 파일을 저장하는 기능인 것 같습니다. .cypher에 대한 기능도 해보겠습니다.
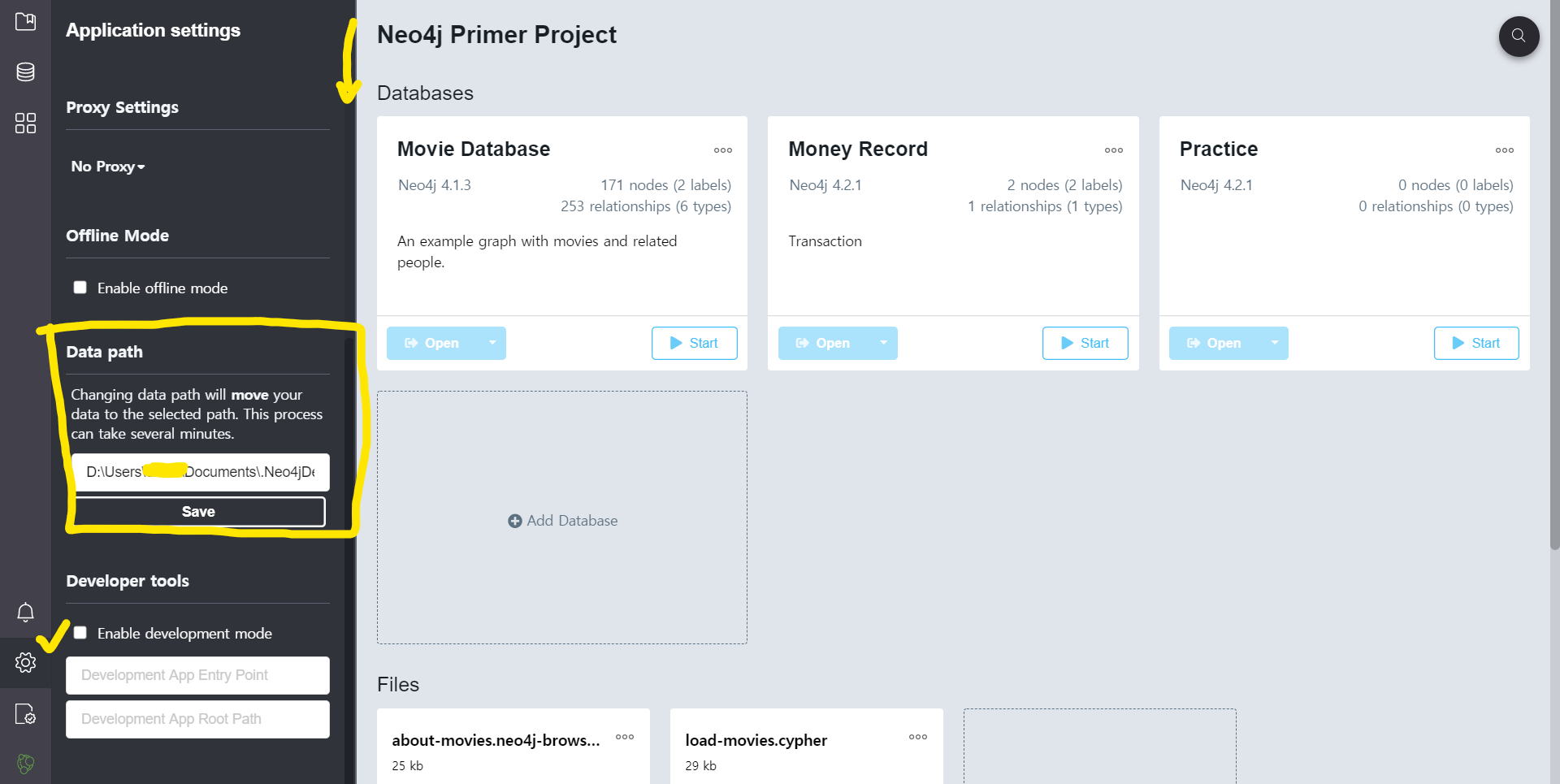
기억에 최초에 설치할때도 나왔던거 같지만, 혹시나 변경하고 싶다면 본인이 원하는 위치로 바꾸면 됩니다. 설명에는 다음과 같이 써있습니다.
Changing data path will move your data to the selected path. This process can take several minutes.
데이터 위치를 변경하는 것은 당신의 데이터를 선택된 위치에 데이터를 옮길 것이다. 이 과정은 몇분 걸릴 것이다.
즉, 최초에 설정하고 옮긴다 해도 데이터가 소실되지 않는다는 뜻입니다.
데이터 베이스 만들어보기
그냥 막 만드는 거지.
데이터 베이스 만들기는 그렇게 특별할 것도 없습니다. 그냥 클릭하고 만들면 됩니다.

레벨 체계로 보면 프로젝트 -> 데이터베이스 -> 그 안에서 작업 순서로 볼 수 있습니다.


데이터 베이스 만들기는 정말 어려운 점은 없었습니다. 책의 내용을 진행하기 위해서 다른 플러그인 들을 설치해보도록 하겠습니다.
플러그인 설치하기.
조금 헷갈리는 체계. 메인에도 깔고 각 데이터베이스에도 깔아야 하는 듯. APOC과 Graph Data Science Library
진행을 위해 플러그인을 깔아 줍니다.
설치할 플러그인
- APOC
- Graph Data Science Library
APOC이란?
APOC은 Awosome Procedure on Cypher의 약자입니다. Apoc은 Neo4J 애드온 으로서, 수백개의 기능과 절차를 제공합니다.1 한마디로 "Cypher를 위핸 개쩌는 기능들의 모음" 정도로 해석하면 될것 같습니다. 이후 용법은 진행하면서, 기타등등 나올 것 같습니다.
Graph Data Science Library란?
The Neo4j Graph Data Science (GDS) library provides extensive analytical capabilities centered around graph algorithms. The library includes algorithms for community detection, centrality, node similarity, path finding, and link prediction, as well as graph catalog procedures designed to support data science workflows and machine learning tasks over your graphs. All operations are designed for massive scale and parallelisation, with a custom and general API tailored for graph-global processing, and highly optimised compressed in-memory data structures.
GDS 라이브러리는 그래프 알고리즘에 집중된 다양한 분석 능력을 제공한다. 이 라이브러리는 데이터 사이언스 워크플로우, 그래프 위의 머신러닝을 돕도록 설계된 카탈로그된 절차 뿐만 아니라, 커뮤니티 디텍션, 중앙화, 노드 유사점, 길찾기(path finding) 그리고 연결점 예측을 포함한다. 모든 수행은 graph-global 계산과 매우 최적화된 압축 메모리 구조를 다루기 위한 맞춤형 그리고 일반적인 API와 함께, 커다란 스케일과 평행화(병렬 계산?)을 위해 제작 되었다.
한마디로 빠르게 여러가지 데이터 계산을 뚝딱뚝딱하는 라이브러리라고 보면 될 것 같습니다. 그럼 설치해 보겠습니다.
설치
메인에 설치 -> 각 DB에 가서 설치
또다시 패를 깔자면 저도 처음입니다. 그래서 제 초점은 어떻게든 돌아가게만 하는 것 입니다. 그냥 이렇게 하다보니 되더라고요 방식으로 진행해 보도록 하겠습니다.
메인에 설치하기
메인 화면에 해당하는 위치에 한번 설치하고 각 데이터베이스에 설치해줘야 합니다.


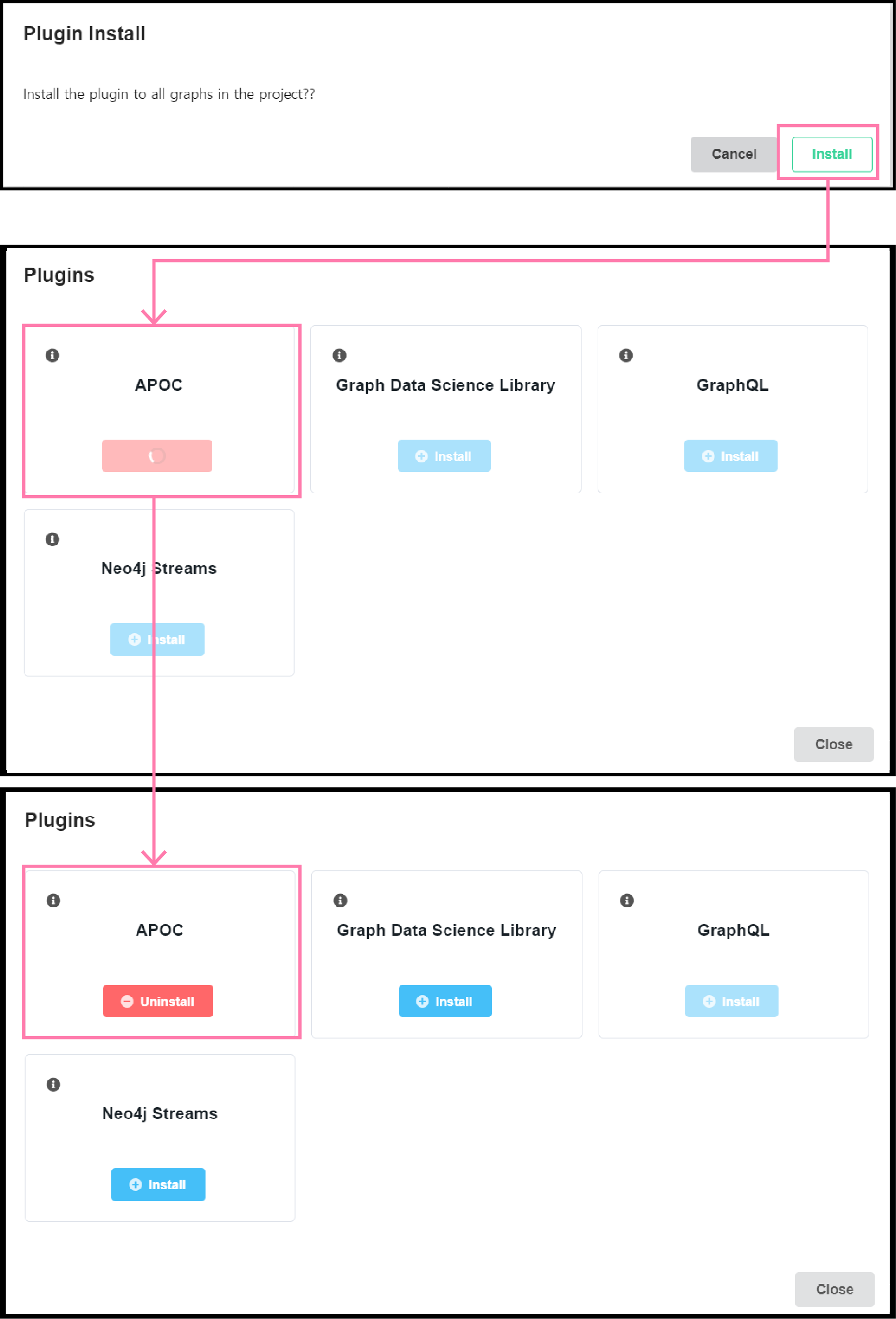
설치는 매우 간단합니다. 그냥 몇번 클릭만 하면 됩니다. GDS는 동일하니 넘어가도록 하겠습니다.
각 DB에 설치(확인)하기
지난번엔 다 설치해야 했는데 다 설치되어 있네요

지난번에 테스트 했을땐 안깔려 있었는데, 이번엔 메인에 하면 되네요. 어쩃든 이렇게 필요한 프로그램 설치는 끝났습니다. 이렇게 본격적으로 알고리즘을 돌릴 준비가 끝났습니다.
앞으로 실행할 알고리즘 리스트

이전 글에서도 얘기했듯, 현재 컴퓨터 설정상 Spark를 실행하기 어렵습니다. 따라서 Neo4j에 관한것을 조금씩의 설명과 함께 진행해 나가도록 하겠습니다.
'아카이브 > 프로그래밍' 카테고리의 다른 글
| [그래프 데이터베이스][무작정해보기] [6/30] A*(A-star) Algorithm 그림으로 이해하기. (0) | 2021.01.10 |
|---|---|
| [그래프 데이터베이스][무작정해보기] [5/30] Shortest Path Algorithm 사용해보기 (1) | 2021.01.03 |
| [그래프 데이터베이스][무작정해보기] [4/30]Dijkstra's Algorithm(다익스트라, 데이크스트라 알고리즘) (0) | 2021.01.02 |
| [그래프 데이터베이스][무작정해보기] [3/30] 웹상의 CSV로 부터 Graph 생성하기 (1) | 2021.01.01 |
| [그래프 데이터베이스][무작정해보기] [1/30] 그래프 DB 시작: 그래프 DB란? -> Neo4j Desktop 설치 (0) | 2020.12.24 |
![[그래프 데이터베이스][무작정해보기] [5/30] Shortest Path Algorithm 사용해보기](http://i1.daumcdn.net/thumb/C176x120.fwebp.q85/?fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcoOLwZ%2FbtqSgLX2tOZ%2FAAAAAAAAAAAAAAAAAAAAAKwSKYlY8i0XGQVHwUMJfrGynGM5NyXpPOsZYkU1aP22%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3D2gdj58QjVah2bOpKLl%252B4wycqilY%253D)
![[그래프 데이터베이스][무작정해보기] [4/30]Dijkstra's Algorithm(다익스트라, 데이크스트라 알고리즘)](http://i1.daumcdn.net/thumb/C176x120.fwebp.q85/?fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcOPgBI%2FbtqR1DUzfjW%2FAAAAAAAAAAAAAAAAAAAAAHq88ekuhiB1XZt6-CWkAonavDbSJHisxqSG-Q_r_vVi%2Fimg.gif%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DwWCxoj8pF%252BEvwth%252Bd%252Bh5MY4nw1A%253D)
![[그래프 데이터베이스][무작정해보기] [3/30] 웹상의 CSV로 부터 Graph 생성하기](http://i1.daumcdn.net/thumb/C176x120.fwebp.q85/?fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbopCqr%2FbtqSjz97iNb%2FAAAAAAAAAAAAAAAAAAAAAFC0H8B98eklDhsXG02hsGDfxwH2IoHCZ2XBGiKNa_hq%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DvptsVQx0zC0s%252Fc52Zxizb7Ak1Y0%253D)
![[그래프 데이터베이스][무작정해보기] [1/30] 그래프 DB 시작: 그래프 DB란? -> Neo4j Desktop 설치](http://i1.daumcdn.net/thumb/C176x120.fwebp.q85/?fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbRugis%2FbtqRjgFpyAG%2FAAAAAAAAAAAAAAAAAAAAADxzhQ7HYLMOBfq2wHmIKOdY99SO69SoBG_cbQzXouvV%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DmOE%252B1LTiuoGjivH%252BZax%252B%252BabU9Zo%253D)