개요.
사이퍼 언어 기초적인 구조를 이해해보고, 이를 응용해 2촌 찾아 보기를 해보겠습니다.
Cypher란 무엇인가?
※파파고의 도움을 받아 공식 사이트 문장을 번역하였습니다.
Cypher is a declarative graph query language that allows for expressive and efficient querying updating and administering of the graph. It is designed to be suitable for both developers and operations professionals. Cypher is designed to be simple, yet powerful; highly complicated database queries can be easily expressed, enabling you to focus on your domain, instead of getting lost in database access.
Cypher is inspired by a number of different approaches and builds on established practices for expressive querying. Many of the keywords, such as WHERE and ORDER BY, are inspired by SQL. Pattern matching borrows expression approaches from SPARQL. Some of the list semantics are borrowed from languages such as Haskell and Python. Cypher’s constructs, based on English prose and neat iconography, make queries easy, both to write and to read.
Cypher는 그래프의 표현적이고 효율적인 쿼리 업데이트 및 관리를 허용하는 선언적 그래프 쿼리 언어입니다. 개발자와 운영 전문가 모두에게 적합하도록 설계되었습니다. Cypher는 단순하지만 강력하도록 설계되었으며, 매우 복잡한 데이터베이스 쿼리를 쉽게 표현할 수 있어 데이터베이스 액세스에서 길을 잃지 않고 도메인에 집중할 수 있습니다.
Cypher는 많은 다른 접근법에서 영감을 받았고 표현적인 질의에 대해 확립된 관행을 기반으로 합니다. WHERE와 ORDER BY와 같은 많은 키워드는 SQL에서 영감을 받았습니다. 패턴 일치는 SPARQL에서 표현식을 차용합니다. 목록 의미론 중 일부는 Haskell 및 Python과 같은 언어에서 차용됩니다. 영어 산문과 깔끔한 아이콘그래픽에 바탕을 둔 Cypher의 구성은 쓰고 읽기 쉬우며 쿼리를 쉽게 합니다.
몇몇 눈에 띄는 단어들이 있습니다.
- 표현적이고 효율적이다
- 선언적인 그래프 쿼리 언어
- 기존 언어에서 영감을 받았다
이중 선언적인 그래프 쿼리 언어라는 뜻을 찾아보았습니다.
Declarative query languages let users express what data to retrieve, letting the engine underneath take care of seamlessly retrieving it.
선언적인 쿼리 언어는 사용자가 얻고자 하는 데이터를 표현하게 하며, 아래 깔린 엔진이 끊임없이 데이터를 받아오도록 한다1.
한마디로 말하면 "사용자는 얻고자 하는 데이터만 얘기하고, 복잡한 방법은 엔진이 알아서 할게" 정도로 해석할 수 있습니다.
Cypher의 구조
Cypher borrows its structure from SQL — queries are built up using various clauses.
Clauses are chained together, and they feed intermediate result sets between each other. For example, the matching variables from one MATCH clause will be the context that the next clause exists in.
The query language is comprised of several distinct clauses. These are discussed in more detail in the chapter on Clauses.
The following are a few examples of clauses used to read from the graph:
-
MATCH: The graph pattern to match. This is the most common way to get data from the graph.
-
WHERE: Not a clause in its own right, but rather part of MATCH, OPTIONAL MATCH and WITH. Adds constraints to a pattern, or filters the intermediate result passing through WITH.
-
RETURN: What to return.
Cypher는 SQL에서 구조를 차용합니다. - 쿼리는 다양한 절을 사용하여 작성됩니다.
절은 서로 연결되어 있으며 중간 결과 집합을 서로 연결합니다. 예를 들어, 하나의 MATCH 절의 일치 변수는 다음 절이 존재하는 컨텍스트가 됩니다.
쿼리 언어는 몇 개의 개별 절로 구성됩니다. 이러한 내용은 절에 대한 장에서 더 자세히 논의됩니다.
다음은 그래프에서 읽는 데 사용되는 절의 몇 가지 예입니다.
- MATCH: 일치시킬 그래프 패턴입니다. 이것은 그래프에서 데이터를 가져오는 가장 일반적인 방법입니다.
- WHERE: 그 자체로 하나의 조항이 아니라 MATCH, OPTIONAL MATCH 및 WITH의 일부입니다. 패턴에 제약 조건을 추가하거나 WITH를 통과하는 중간 결과를 필터링합니다.
- RETURN: 반환할 무언가.
그래프 만들기
연습용 데이터베이스 만들기.

create DATABASE cypherpractice;저는 연습하고 지우기 위해서 연습용 데이터 베이스를 만들었습니다. 만드신 후에, 그 데이터 베이스로 이동해야 하는 것 잊지 마세요.
친구 그래프 만들기
CREATE (john:Person {name: 'John'})
CREATE (joe:Person {name: 'Joe'})
CREATE (steve:Person {name: 'Steve'})
CREATE (sara:Person {name: 'Sara'})
CREATE (maria:Person {name: 'Maria'})
CREATE (john)-[:FRIEND]->(joe)-[:FRIEND]->(steve)
CREATE (john)-[:FRIEND]->(sara)-[:FRIEND]->(maria)
위 Cypher 문장을 실행하면 왼쪽과 같은 그래프를 얻으셨을 겁니다. 이는 오른쪽의 구조와 동일합니다. 각 노드들은 Person 이라는 Label을 지니고 있으며, 현재 그 속성은 'name'만 가지고 있습니다. relationship은 Friend라벨을 가지고 있습니다. 결과는 그렇고 하나하나 설명해 보도록 하겠습니다.
우선 위의 사이퍼 구문을 살펴보면 크게 두가지로 이루어져 있습니다.
- 노드 생성
- 관계 생성
이를 나누어 설명해 보겠습니다.
노드생성
CREATE (john:Person {name: 'John'})
CREATE (joe:Person {name: 'Joe'})
CREATE (steve:Person {name: 'Steve'})
CREATE (sara:Person {name: 'Sara'})
CREATE (maria:Person {name: 'Maria'})기본 구문을 해석해보겠습니다.
CREATE ()
노드를 생성하는 기본 구문입니다. 아무 값도 없지만 노드는 생성됩니다.
노드에 속성을 입히는건 오늘 목표가 아니니까 넘어가도록 하겠습니다.
CREATE (:Person)
'Person'이라는 라벨을 가진 노드를 만들어라. Person라벨을 가진 노드가 생성되었습니다.
CREATE (:Person {name:'me'})
name 속성에 me라는 값을 가진 Person 노드를 만들어라
사실 여기까지만 해도 노드 자체를 만드는 것은 문제 없습니다. 하지만 우리는 관계까지 정의해야합니다. 이를 위해선 A노드 에서 B노드는 C라는 관계로 연결해라 라는 문장이 필요합니다. 이를 위해서 A노드와 B노드를 변수로 지정해 두어야 합니다.
CREATE (john:Person {name: 'John'})Person이라는 노드를 만들고, 그 안의 name이라는 속성을 만들고 'John'을 기입해라. 그리고 john이라는 변수에 지금 생성된 노드를 할당해라. 위의 Cypher는 이렇게 해석할 수 있습니다.
관계생성
CREATE (a)-[:c]->(b)가장 기본 구문은 다음과 같습니다. a와 b는 c의 관계이다. 예를 들면, John(a)은 Maria(b)와 결혼했다(c) 라는 관계도 구성할 수 있습니다. 여기서 a와,b는 변수입니다. Neo4j에서는 노드가 먼저 생성되어야 관계를 형성할 수 있습니다. 그럼 아래 내용을 다시 보겠습니다.
CREATE (john:Person {name: 'John'})
CREATE (joe:Person {name: 'Joe'})
CREATE (steve:Person {name: 'Steve'})
CREATE (sara:Person {name: 'Sara'})
CREATE (maria:Person {name: 'Maria'})CREATE (john)-[:FRIEND]->(joe)-[:FRIEND]->(steve)
CREATE (john)-[:FRIEND]->(sara)-[:FRIEND]->(maria)예제 내용을 보면 노드들을 만드는 내용이 먼저 나오고, 만들어진 노드들을 john,joe,steve,sara,maria라는 변수에 할당합니다. 그 후 다음과 같은 구조를 통해 관계를 만들어 냅니다.
CREATE (a)-[:d]->(b)-[:d]->(c)
a는 b와 d의 관계이며 b는 c와 d의 관계이다.
CREATE (john)-[:FRIEND]->(joe)-[:FRIEND]->(steve)john은 joe와 친구이며, joe는 steve와 친구이다. 즉, 앞에서 노드를 만들때 변수에 할당한 이유는 관계를 만들기 위해서 입니다.
2촌 찾기

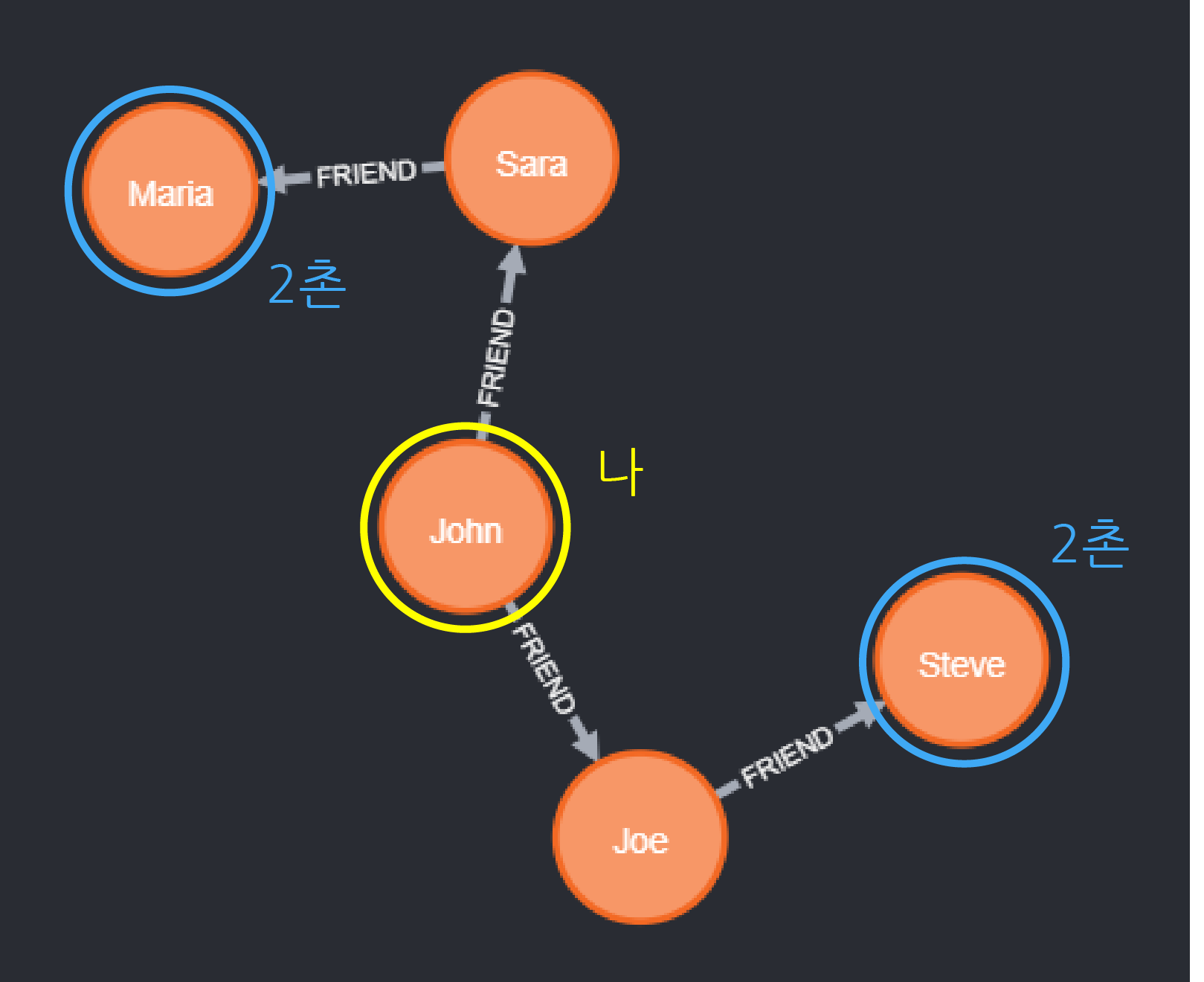
1,2촌 하면 왠지 싸이월드가 생각납니다. 아재감성. SNS는 어떤식으로든 사람들간의 관계망을 서버안에 유지할 수 밖에 없을 것입니다. 각설하고 그래프 데이터 베이스에서 찾아보도록 하겠습니다.
기초 Cypher 문법 이용하기
MATCH (a)-[:rel]->()-[:rel]->(b)
RETURN a.property, b.property어떤 rel(relation)을 두번 거쳤을때 나타나는 a와 b 값을 찾아 그 property를 반환하라. 중간에 비어있는 ()이 있는데, 관계라는 것이 노드 없이 존재 할 수 없는 걸 생각해 봤을때 이해할 수 있는 부분입니다.
MATCH (john {name: 'John'})-[:FRIEND]->()-[:FRIEND]->(fof)
RETURN john.name, fof.nameMATCH (john:Person {name: 'John'})-[:FRIEND]->()-[:FRIEND]->(fof:Person)
RETURN john.name, fof.name| john.name | fof.name |
| "John" | "Maria" |
| "John" |
"Steve" |
위의 두 명령어는 같은 결과를 보여줍니다. 지금 데이터베이스에는 Person이라는 라벨을 가진 노드만 존재하기 때문에 name이 'John'인 노드만 뽑는다고 해도 됩니다. 만약 데이터베이스 안에 Person, Equipment 등과 같이 여러가지 노드 라벨이 존재한다면 꼭 라벨을 지정해줘야 할 것입니다.
MATCH (john {name: 'John'})-[:FRIEND]->()-[:FRIEND]->(fof)
RETURN john.name AS me, fof.name AS `two hops`| me | two hops |
| "John" | "Maria" |
| "John" |
"Steve" |
SQL을 해보신 분들은 친숙하겠지만 Return result as new_name 구조로 테이블의 헤더값을 바꿀 수 있습니다.
two hops의 경우 띄어쓰기를 포함하고 있기 때문에 별도의 조치가 필요했습니다. 이때 유의해야 할 것은, 따옴표(')가 아닌 키보드 좌상단에 있는 어퍼스트로피(`) 입니다. 사실 거의 비슷하게 생겨서 알아먹을수가 없죠.
응용 1 : hop 횟수 사용하기
MATCH (john {name: 'John'})-[:FRIEND*2]->(fof)
RETURN john.name, fof.name위와 같이 rel*n의 방식으로 하나의 노드에서 다른 노드까지 n번 통해야 찾을 수 있는 노드를 보여줄 수도 있습니다.
응용 2 : match, where, return 구문
MATCH (p) -[:FRIEND]->()-[:FRIEND]->(fof)
WHERE p.name ='John'
RETURN p.name, fof.nameSQL과 같이 WHERE를 사용할 수 있습니다. 쉽게 MATCH는 구좌와 변수를 정의, WHERE는 변수의 속성 정의라고 보시면 되겠습니다.
이상 Cypher에서 노드와 관계를 만들고, 원하는 노드들만 추출해 보았습니다. Neo4j 설명에 의하면 자바, 파이썬 등을 기반으로 한 어플리케이션에서도 그래프 데이터베이스 작동이 가능하니, 여러가지 용도로 활용할 수 있을 것 같습니다.
참고자료 및 풋노트
neo4j.com/docs/cypher-manual/current/introduction/
'아카이브 > 프로그래밍' 카테고리의 다른 글
| [그래프 데이터베이스][무작정해보기] [10/30] Relation과 Property로 Query하기 (2) | 2021.01.22 |
|---|---|
| [그래프 데이터베이스][무작정해보기] [9/30] 노드속성을 이용한 쿼리 및 필터 (0) | 2021.01.18 |
| [그래프 데이터베이스][무작정해보기] [7/30] A*(A-star) Algorithm Neo4j에서 실행해보기 (0) | 2021.01.11 |
| [그래프 데이터베이스][무작정해보기] [6/30] A*(A-star) Algorithm 그림으로 이해하기. (0) | 2021.01.10 |
| [그래프 데이터베이스][무작정해보기] [5/30] Shortest Path Algorithm 사용해보기 (1) | 2021.01.03 |
![[그래프 데이터베이스][무작정해보기] [10/30] Relation과 Property로 Query하기](http://i1.daumcdn.net/thumb/C176x120.fwebp.q85/?fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FmOzov%2FbtqUpaolQSn%2FAAAAAAAAAAAAAAAAAAAAANQNjPOijpbtTVhXaRv65RNYO2stCcdzCtujYcywmwr4%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DdR6lrOypL%252BPC6makiHiLXjHpf38%253D)
![[그래프 데이터베이스][무작정해보기] [9/30] 노드속성을 이용한 쿼리 및 필터](http://i1.daumcdn.net/thumb/C176x120.fwebp.q85/?fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbIVEoT%2FbtqTYR3et3R%2FAAAAAAAAAAAAAAAAAAAAAFovrFS9a9evryaeqrHAXQv1BZUheXd9EeWlooXBXeUy%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3D%252BoFXjX0JgucZ1ZnFWT5Z%252Fj6qj4k%253D)
![[그래프 데이터베이스][무작정해보기] [7/30] A*(A-star) Algorithm Neo4j에서 실행해보기](http://i1.daumcdn.net/thumb/C176x120.fwebp.q85/?fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdPM03e%2FbtqTcRwfLcU%2FAAAAAAAAAAAAAAAAAAAAAH5v8PDpzSTdapZYrxOzcWz3JG47EytiJtIl51uoNlg9%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DHHsxkQpU8b4G2ggsOLfNubJuAOo%253D)
![[그래프 데이터베이스][무작정해보기] [6/30] A*(A-star) Algorithm 그림으로 이해하기.](http://i1.daumcdn.net/thumb/C176x120.fwebp.q85/?fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FQxfiZ%2FbtqSZyc1Etr%2FAAAAAAAAAAAAAAAAAAAAAOpOvubQY5aOHUXchmFRPS4hqgKYYSHbxiiY8oEzgax5%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DDnE7%252Fu4u2Pr5GWMQFs%252Fgm9hgHT4%253D)